10.04.2026
Datenanalyse im Support: Prozesse 2026 effizient optimieren

Erfahren Sie, wie Datenanalyse Support-Prozesse optimiert: KPIs, Machine Learning, Praxisbeispiele und Erfolgsfaktoren für IT- und Support-Manager in Deutschland.
Datenanalyse im Support: Prozesse 2026 effizient optimieren
Viele Unternehmen unterschätzen das Potenzial datenbasierter Methoden im Support. Empirische Beispiele zeigen signifikante Effizienzsteigerungen durch strukturierte Analyse von Supportdaten. Während traditionelle Ansätze oft reaktiv bleiben, ermöglicht systematische Datenauswertung proaktive Optimierung. Dieser Artikel erklärt die vier Analysearten, zeigt zentrale KPIs für Erfolgsmessung und präsentiert praxiserprobte Methoden. Sie erfahren, welche Technologien deutsche Unternehmen nutzen, welche messbaren Erfolge möglich sind und wo typische Fallstricke lauern. IT- und Support-Manager erhalten konkrete Ansatzpunkte für datengetriebene Prozessverbesserungen.
Inhaltsverzeichnis
Wichtige Erkenntnisse zur datenbasierten Support-Optimierung
Grundlagen der Datenanalyse im Support verstehen
Technologien und Methoden zur Datenanalyse im Support
Praxisbeispiele und messbare Erfolge deutscher Unternehmen
Herausforderungen, Risiken und Erfolgsfaktoren bei der Implementierung
Mit Datenanalyse den Kundenservice automatisieren und verbessern
Häufig gestellte Fragen zur Datenanalyse im Support
Wichtige Erkenntnisse zur datenbasierten Support-Optimierung
Point | Details |
|---|---|
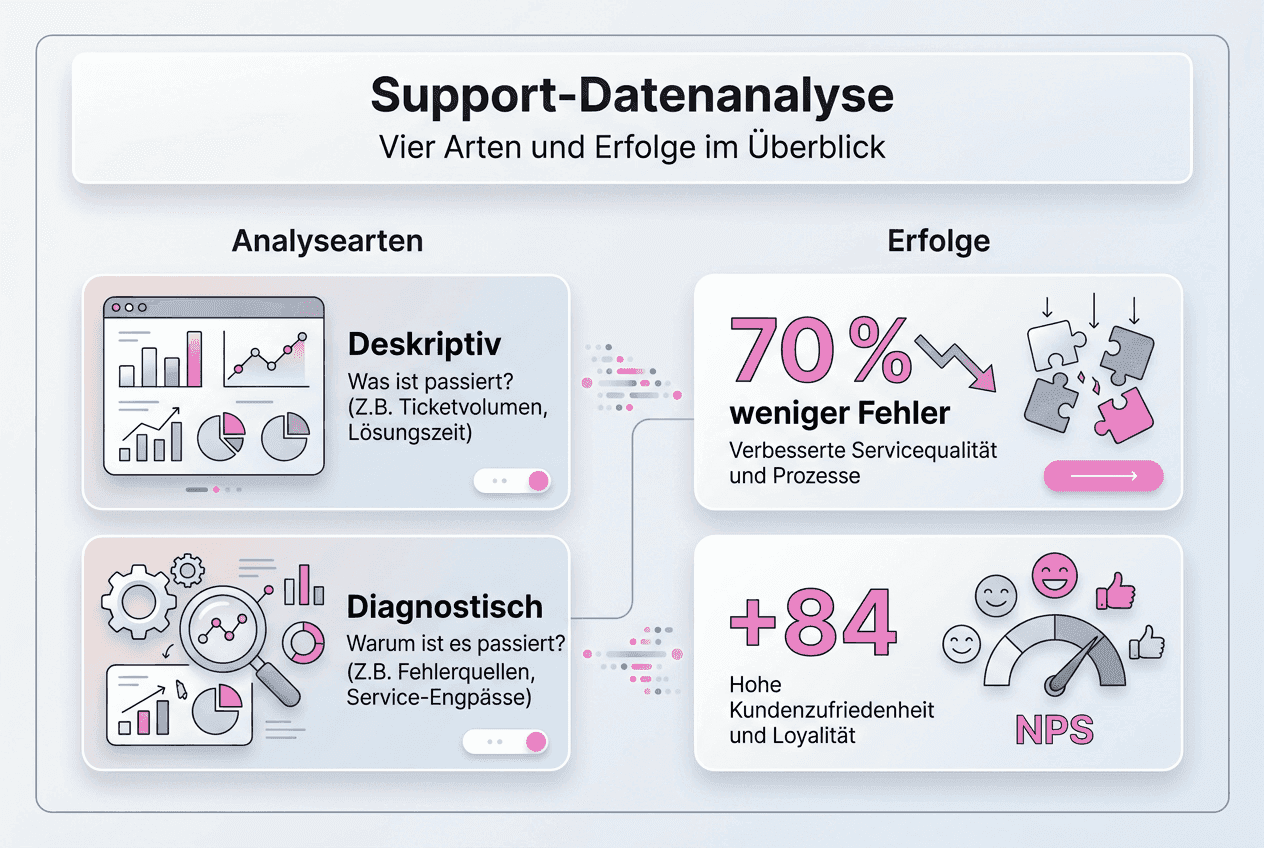
Vier Analysearten | Deskriptive, diagnostische, prädiktive und präskriptive Analytics bilden das methodische Fundament |
Zentrale KPIs | CSAT, First Response Time, Time to Resolution und First Contact Resolution messen Servicequalität präzise |
Machine Learning | Automatisierte Ticket-Klassifizierung mit BERT oder GPT steigert Zuordnungsgenauigkeit erheblich |
Messbare Erfolge | Deutsche Unternehmen reduzieren Fehlzuweisungen um über 70 % und sparen Monate an Bearbeitungszeit |
Kritische Faktoren | Datenqualität, DSGVO-Konformität und Mitarbeiterakzeptanz entscheiden über nachhaltige Implementierung |
Grundlagen der Datenanalyse im Support verstehen
Datenanalyse im Kundenservice basiert auf vier methodischen Säulen. Deskriptive, diagnostische, prädiktive und präskriptive Analytics erfüllen unterschiedliche Zwecke in der Prozessoptimierung. Deskriptive Analyse beschreibt den aktuellen Zustand durch Auswertung historischer Daten. Sie beantwortet die Frage, was passiert ist.
Diagnostische Analyse geht einen Schritt weiter und identifiziert Ursachen für beobachtete Muster. Warum steigt die Ticket-Anzahl zu bestimmten Zeiten? Welche Produktmerkmale erzeugen die meisten Supportanfragen? Diese Erkenntnisse bilden die Basis für gezielte Verbesserungen. Prädiktive Analyse nutzt statistische Modelle und Machine Learning, um zukünftige Entwicklungen vorherzusagen. Präskriptive Analyse empfiehlt konkrete Handlungen basierend auf den Vorhersagen.
Wesentliche Kennzahlen messen die Servicequalität objektiv. CSAT, First Response Time, Time to Resolution und First Contact Resolution sind Standardmetriken in professionellen Support-Organisationen. Customer Satisfaction Score erfasst die Kundenzufriedenheit direkt nach Interaktionen. First Response Time misst, wie schnell Kunden eine erste Antwort erhalten. Time to Resolution zeigt die durchschnittliche Bearbeitungsdauer bis zur Lösung.
First Contact Resolution gibt an, welcher Anteil der Anfragen beim ersten Kontakt abschließend bearbeitet wird. Höhere FCR-Werte bedeuten effizientere Prozesse und zufriedenere Kunden. Das Ticketvolumen selbst liefert Hinweise auf Produktqualität, Dokumentationslücken oder saisonale Muster. Diese Metriken ermöglichen datenbasierte Entscheidungen statt Bauchgefühl.
Datenquellen im Support sind vielfältig und reichhaltig. Ticketsysteme speichern strukturierte Informationen zu Anfragen, Bearbeitungszeiten und Lösungswegen. Kundenfeedback aus Umfragen, Bewertungen und direkten Kommentaren ergänzt quantitative Daten um qualitative Perspektiven. Chat-Protokolle, E-Mail-Verläufe und Telefonaufzeichnungen bieten zusätzlichen Kontext. Support-Tools wie CRM-Systeme, Helpdesk-Software und Wissensmanagement-Plattformen generieren kontinuierlich verwertbare Daten.
Die Integration dieser Quellen schafft ein ganzheitliches Bild der Support-Performance. Automatisierter Kundenservice profitiert besonders von strukturierten, sauberen Daten. Ohne solide Datenbasis bleiben Optimierungsansätze spekulativ. Mit systematischer Auswertung identifizieren wir Engpässe, erkennen Trends und messen den Erfolg von Verbesserungsmaßnahmen präzise.
Zentrale Vorteile der datenbasierten Support-Optimierung:
Objektive Erfolgsmessung durch quantifizierbare KPIs statt subjektiver Einschätzungen
Frühzeitige Erkennung von Problemen und Trends durch kontinuierliches Monitoring
Gezielte Ressourcenallokation basierend auf tatsächlichem Bedarf und Prioritäten
Fundierte Entscheidungsgrundlage für Prozessänderungen und Investitionen
Nachweisbare Verbesserungen für Management und Stakeholder
Die Kombination aus robusten Datenquellen, aussagekräftigen Kennzahlen und methodischer Analyse bildet das Fundament für kontinuierliche Prozessverbesserung. Weitere Informationen zu Customer Service Analytics zeigen die praktische Anwendung dieser Grundlagen.
Technologien und Methoden zur Datenanalyse im Support
Moderne Technologien automatisieren die Auswertung großer Datenmengen im Support. Machine-Learning-Modelle wie BERT oder GPT klassifizieren eingehende Tickets präzise und leiten sie automatisch an die richtige Abteilung weiter. Diese Sprachmodelle verstehen Kontext und Intention der Kundenanfragen deutlich besser als regelbasierte Systeme. Die Genauigkeit der Zuordnung steigt erheblich, Fehlzuweisungen sinken dramatisch.

Sentiment-Analyse wertet die emotionale Färbung von Kundenäußerungen aus. Ist der Kunde frustriert, neutral oder zufrieden? Diese Information hilft, Prioritäten zu setzen und kritische Fälle schneller zu bearbeiten. Negative Stimmungen signalisieren mögliche Eskalationen, positive Rückmeldungen zeigen erfolgreiche Interaktionen. Die systematische Auswertung von Sentiments liefert Qualitätseinblicke, die in aggregierten Metriken oft untergehen.
Predictive Analytics identifizieren Risiken, bevor sie zu Problemen werden. Vorhersagen mit 88 % Genauigkeit ermöglichen proaktive Maßnahmen bei drohenden Eskalationen. Welche Tickets werden wahrscheinlich eskalieren? Welche Kunden könnten abwandern? Welche Produkte erzeugen in naher Zukunft erhöhten Support-Bedarf? Diese Fragen beantwortet prädiktive Analyse mit statistischer Präzision.
Automatisierte Prozesse reduzieren manuelle Arbeit erheblich. Routineanfragen werden ohne menschliches Eingreifen beantwortet. Standardinformationen liefern Chatbots rund um die Uhr. Komplexe Anfragen erreichen qualifizierte Mitarbeiter direkt, ohne Umwege über First-Level-Support. Die Servicequalität steigt, während gleichzeitig Ressourcen für anspruchsvolle Aufgaben frei werden.
Implementierung moderner Analysemethoden folgt strukturierten Schritten:
Datenquellen identifizieren und konsolidieren für ganzheitliche Auswertung
Relevante KPIs definieren, die tatsächliche Geschäftsziele abbilden
Geeignete Tools und Technologien auswählen, die zu Infrastruktur und Anforderungen passen
Pilotprojekte starten, um Ansätze zu validieren und Erfahrungen zu sammeln
Skalierung auf weitere Bereiche nach erfolgreicher Testphase
Kontinuierliches Monitoring und Optimierung der Modelle sicherstellen
Training und Monitoring von KI-Modellen sind entscheidend für nachhaltige Qualität. Modelle müssen regelmäßig mit neuen Daten trainiert werden, um aktuell zu bleiben. Drifts in der Datenverteilung oder veränderte Kundenerwartungen erfordern Anpassungen. Ohne systematisches Monitoring verschlechtert sich die Performance schleichend.
Profi-Tipp: Etablieren Sie klare Feedback-Schleifen zwischen automatisierten Systemen und Support-Mitarbeitern. Wenn KI-Klassifizierungen korrigiert werden, sollten diese Korrekturen ins Modelltraining einfließen. So verbessert sich die Genauigkeit kontinuierlich durch reale Nutzung. Transparente Metriken zur Modell-Performance schaffen Vertrauen und ermöglichen frühzeitige Intervention bei Qualitätsproblemen.
Die Integration verschiedener Technologien schafft Synergien. Machine Learning klassifiziert, Sentiment-Analyse priorisiert, Predictive Analytics warnt vor Risiken. Zusammen bilden sie ein leistungsfähiges System für datengetriebenen Support. Best Practices für KI im Unternehmen helfen bei der erfolgreichen Implementierung dieser Technologien.
Weitere Details zur Ticket-Klassifizierung mit KI zeigen konkrete Anwendungsszenarien und technische Ansätze für verschiedene Unternehmensgrößen und Branchen.
Praxisbeispiele und messbare Erfolge deutscher Unternehmen
Deutsche Unternehmen erzielen beeindruckende Ergebnisse durch datenbasierte Support-Optimierung. Geberit reduzierte falsch zugeordnete Anfragen um über 70 % und ersparte sich drei Monate Bearbeitungszeit. Die automatisierte Klassifizierung mit Machine Learning eliminierte manuelle Zuordnungsfehler nahezu vollständig. Tickets erreichen jetzt sofort die richtige Fachabteilung.
Der Telekommunikationsanbieter Fibrus steigerte seinen Net Promoter Score von minus 28 auf plus 56 durch datengetriebene Prozessverbesserungen. Gleichzeitig sanken Kundenkontakte um 30 %, weil Probleme präziser und schneller gelöst wurden. Weniger Kontakte bei höherer Zufriedenheit zeigen echte Qualitätssteigerung.
Messbare Erfolge in verschiedenen Dimensionen:
Kennzahl | Verbesserung | Unternehmen |
|---|---|---|
Fehlzuweisungen | Reduktion um 70 % | Geberit |
Zeitersparnis | 3 Monate eingespart | Geberit |
Net Promoter Score | Von minus 28 auf plus 56 | Fibrus |
Kundenkontakte | Reduktion um 30 % | Fibrus |
Personalkosten | Einsparung bis 50 % | Verschiedene |
Personalkosten sinken durch Automatisierung signifikant. Routineanfragen verarbeiten digitale Assistenten ohne menschliches Eingreifen. Support-Mitarbeiter konzentrieren sich auf komplexe Fälle, die menschliche Expertise erfordern. Die Produktivität steigt, während Personalkosten um bis zu 50 % sinken. Diese Einsparungen amortisieren Investitionen in Analysetechnologie schnell.
Datenbasierte Maßnahmen bringen rasche Entlastung. Bereits in den ersten Monaten nach Implementierung zeigen sich messbare Verbesserungen. Die Ticket-Bearbeitungszeit sinkt, weil Anfragen präziser zugeordnet werden. Die Lösungsquote beim Erstkontakt steigt, weil relevante Informationen sofort verfügbar sind. Mitarbeiter arbeiten effizienter, Kunden erhalten schnellere Antworten.
Erfolgsfaktoren aus den Praxisbeispielen:
Klare Zielsetzung mit messbaren KPIs vor Projektstart
Schrittweise Implementierung statt Big-Bang-Ansatz
Enge Einbindung der Support-Mitarbeiter in Designentscheidungen
Kontinuierliches Training der KI-Modelle mit realen Daten
Regelmäßige Erfolgsmessung und Anpassung der Strategie
Profi-Tipp: Starten Sie mit einem klar abgegrenzten Pilotbereich, in dem Sie schnell Erfolge demonstrieren können. Ein erfolgreicher Pilot überzeugt Skeptiker und schafft Rückhalt für die Ausweitung auf weitere Bereiche. Dokumentieren Sie Verbesserungen präzise mit vorher/nachher Vergleichen, um den Business Case zu untermauern.
Beispiele für Automatisierung im Büro zeigen weitere Anwendungsfälle jenseits des Supports. Die Prinzipien datenbasierter Optimierung gelten bereichsübergreifend. Weitere Informationen zur Erfolgsmessung von KI im Support bieten vertiefte Einblicke in Metriken und Bewertungsmethoden.
Herausforderungen, Risiken und Erfolgsfaktoren bei der Implementierung
Datenqualität entscheidet über Zuverlässigkeit der Analysen. Unvollständige, inkonsistente oder fehlerhafte Daten führen zu falschen Schlussfolgerungen. Garbage in, garbage out gilt besonders bei Machine Learning. Investitionen in Datenbereinigung und Qualitätssicherung zahlen sich langfristig aus. Ohne saubere Datenbasis bleiben selbst ausgefeilte Algorithmen wirkungslos.
Datensilos erschweren ganzheitliche Auswertung erheblich. Wenn Ticketsystem, CRM und Wissensmanagement isoliert arbeiten, fehlt der übergreifende Blick. Integration verschiedener Systeme erfordert technischen Aufwand, schafft aber erst die Voraussetzung für umfassende Analyse. Fragmentierte Daten liefern fragmentierte Erkenntnisse.
Vertrauen in KI-Systeme muss aktiv aufgebaut werden. Herausforderungen umfassen Datenqualität, Datensilos, KI-Vertrauen und Investitionskosten. Transparente Modelle, die ihre Entscheidungen erklären können, fördern Akzeptanz. Human-in-the-Loop-Ansätze kombinieren KI-Effizienz mit menschlicher Kontrolle. Support-Mitarbeiter müssen KI als Unterstützung erleben, nicht als Bedrohung.
Hohe Anfangsinvestitionen erfordern solide Business Cases. Technologie, Integration, Training und Change Management kosten Geld und Zeit. Der Return on Investment zeigt sich oft erst nach Monaten. Klare Zielsetzungen und realistische Erwartungen sind essentiell. Überzogene Versprechen führen zu Enttäuschungen und gefährden die Akzeptanz.
Spezifische Anforderungen für deutsche Unternehmen:
DSGVO-Konformität bei Verarbeitung von Kundendaten und Trainingsmaterial
Integration in bestehende ITSM-Systeme ohne Disruption laufender Prozesse
Berücksichtigung von Betriebsratsrichtlinien bei Mitarbeitermonitoring
Mehrsprachigkeit für internationale Konzerne mit deutschen Niederlassungen
Hosting-Optionen in deutschen Rechenzentren für sensible Daten
Falsche Vorhersagen bergen Risiken für Kundenbeziehungen. Wenn prädiktive Modelle Eskalationen fälschlicherweise prognostizieren, verschwenden Teams Ressourcen. Wenn echte Risiken übersehen werden, eskalieren Probleme unbemerkt. Regelmäßige Validierung der Modellgenauigkeit ist unerlässlich. Schwellenwerte für Interventionen müssen sorgfältig kalibriert werden.
Profi-Tipp: Binden Sie Support-Mitarbeiter von Anfang an in die Implementierung ein. Ihre praktische Erfahrung identifiziert Stolpersteine, die in theoretischen Konzepten übersehen werden. Schulungen sollten nicht nur Bedienung, sondern auch Hintergründe vermitteln. Verstehen Mitarbeiter, wie KI-Systeme funktionieren, nutzen sie diese effektiver und vertrauen den Ergebnissen mehr.
Checkliste für KI im Kundenservice hilft bei systematischer Planung und Risikovermeidung. Weitere Details zu Herausforderungen im Predictive Support bieten vertiefte Perspektiven auf technische und organisatorische Hürden.
Mit Datenanalyse den Kundenservice automatisieren und verbessern
Die vorgestellten Methoden und Technologien setzen Sie mit professioneller Unterstützung effizient um. EcomTask entwickelt maßgeschneiderte KI-Lösungen für automatisierten Support, die nahtlos in Ihre bestehende Infrastruktur integrieren. Unsere digitalen Assistenten analysieren Supportdaten kontinuierlich und optimieren Prozesse automatisch.

Wir kombinieren automatisierten Kundenservice mit intelligenter Datenanalyse für messbare Effizienzsteigerungen. Digitale Assistenten für Kundenservice klassifizieren Tickets präzise, priorisieren kritische Fälle und liefern Mitarbeitern relevante Informationen in Echtzeit. Die Kundenzufriedenheit steigt, während Bearbeitungszeiten sinken.
Unsere Lösungen berücksichtigen DSGVO-Anforderungen von Anfang an. Hosting in deutschen Rechenzentren, transparente Datenverarbeitung und klare Opt-out-Möglichkeiten sind Standard. Intelligence Automation mit KI-Assistenten zeigt drei bewährte Wege, wie Unternehmen von künstlicher Intelligenz profitieren. Vereinbaren Sie ein kostenloses Strategiegespräch, um Ihre individuellen Anforderungen zu besprechen und konkrete Optimierungspotenziale zu identifizieren.
Häufig gestellte Fragen zur Datenanalyse im Support
Was unterscheidet prädiktive von präskriptiver Analyse?
Prädiktive Analyse sagt voraus, was wahrscheinlich passieren wird, basierend auf historischen Mustern und statistischen Modellen. Präskriptive Analyse geht weiter und empfiehlt konkrete Handlungen, um gewünschte Ergebnisse zu erreichen oder Probleme zu vermeiden. Während prädiktive Methoden Risiken identifizieren, zeigen präskriptive Ansätze den optimalen Handlungsweg auf.
Wie lässt sich Datenschutz bei Support-Daten gewährleisten?
DSGVO-konforme Verarbeitung erfordert klare Rechtsgrundlagen, Zweckbindung und technische Schutzmaßnahmen. Personenbezogene Daten sollten pseudonymisiert oder anonymisiert werden, wo möglich. Zugriffskontrolle, Verschlüsselung und regelmäßige Audits schützen sensible Informationen. Kunden müssen über Datenverarbeitung informiert werden und Widerspruchsrechte haben.
Welche KPIs sind für Support-Manager am wichtigsten?
Customer Satisfaction Score misst direkte Kundenzufriedenheit und zeigt Servicequalität. First Contact Resolution gibt an, wie effektiv Probleme beim ersten Kontakt gelöst werden. Time to Resolution zeigt Effizienz der Bearbeitung. Diese drei Metriken bilden zusammen ein ausgewogenes Bild von Qualität und Effizienz im Support.
Wie startet man mit der Datenanalyse im Support?
Beginnen Sie mit einer Bestandsaufnahme vorhandener Datenquellen und aktueller Prozesse. Definieren Sie klare Ziele und relevante KPIs, die Sie verbessern möchten. Wählen Sie einen überschaubaren Pilotbereich für erste Analysen aus. Einfache deskriptive Auswertungen liefern bereits wertvolle Erkenntnisse, bevor Sie in komplexere prädiktive Methoden investieren.
Welche Risiken birgt der Einsatz von KI im Support?
Falsche Klassifizierungen können Tickets an falsche Abteilungen leiten und Bearbeitungszeiten verlängern. Bias in Trainingsdaten führt zu unfairen oder diskriminierenden Entscheidungen. Übermäßige Automatisierung ohne menschliche Kontrolle frustriert Kunden bei komplexen Anliegen. Mangelnde Transparenz untergräbt Vertrauen von Mitarbeitern und Kunden. Regelmäßiges Monitoring und Human-in-the-Loop-Ansätze minimieren diese Risiken.
Wie lange dauert die Implementierung von Analysesystemen?
Ein Pilotprojekt mit begrenztem Scope dauert typischerweise drei bis sechs Monate von Konzeption bis Go-live. Die unternehmensweite Ausrollung erstreckt sich oft über zwölf bis achtzehn Monate, abhängig von Komplexität und Anzahl der zu integrierenden Systeme. Erste messbare Verbesserungen zeigen sich meist nach zwei bis drei Monaten im Pilotbereich.